select * from t_book where id=1; 等价 select * from t_book tb where tb.id=1;
字段取别名:属性 [AS] 属性别名
select tb.bookName [AS] tbNa from t_book tb where tb.id=1;
4.1 查询表内字段
4.1.1 查询所有字段:
1 2 3 4
#select 字段1,字段2,字段3... from 表名; select id,stuName,age,gender,gradeName from t_student; #顺序可调 #select*from 表名; select*from t_student;
4.1.2 查询指定字段:
1 2
select 指定字段1,指定字段3... from 表名; select stuName,gender from t_student;
4.1.3 where条件查询
1 2 3
#select 字段1,字段2... from 表名 where 条件表达式; select*from t_student where id=1; select*from t_student where age>19;
指定条件删除字段:
1
deletefrom t_student where id=4;
4.1.4 带in关键字查询
1 2 3
#select 字段1,字段2,字段3... from 表名 where 字段 [NOT] IN (元素1.元素2…); select*from t_student where age in (18,19); #只能取这两个,不是范围 select*from t_student where age notin (18,19);
4.1.5 带between and的范围查询
1 2 3
#select 字段1,字段2,字段3... from 表名 where 字段 [NOT] BETWEEN 取值a AND 取值b; select*from t_student where age between18and20; #181920 都可以取,是范围 select*from t_student where age notbetween18and20;
4.1.6 带like模糊查询
1 2 3 4 5 6 7
#select 字段1,字段2,字段3... from 表名 where 字段 [NOT] LIKE ‘字符串’; #"%"代表任意字符 '_'代表单个字符,前后都可
select*from t_student where stuName like'张三'; select*from t_student where stuName like'张三%'; #带'张三'开头的 select*from t_student where stuName like'张三_'; #_只能占一个位。多个就写多个_ _ select*from t_student where stuName like'%张三%';
4.1.7 空值查询
1 2 3 4
#select 字段1,字段2,字段3... from 表名 where 字段 IS [NOT] NULL;
select*from t_student where age isNULL; select*from t_student where age isNOTNULL;
4.1.8 带and的多条件查询
1 2 3 4
#select 字段1,字段2,字段3... from 表名 where 条件表达式1AND 条件表达式2AND 条件表达式3AND ... #注意末尾是没有分号的
select*from t_student where age=20and gradeName='大四'
4.1.9 带or的多条件查询
1 2 3 4
#select 字段1,字段2,字段3... from 表名 where 条件表达式1OR 条件表达式2OR 条件表达式3OR ... #或,语句末尾也是无分号;
select*from t_student where age=20or gradeName='大四'
4.1.10 distinct去重复查询
1 2 3
#selectdistinct 字段名 from 表;
selectdistinct age from t_student;
4.1.11 对查询结果排序
1 2 3 4
#select 字段1,字段2,... from 表名 orderby 属性名 [ASC|DESC] #默认升序
select age from t_student orderby age asc;
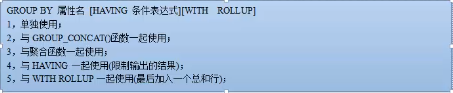
4.1.12 group by 分组查询
一般不单独使用,常和聚合函数一起使用,一定注意使用的时候各个符号。
1 2 3 4 5 6 7 8 9 10 11
#按age分组,看每个(岁数)组有哪些stuName,GROUP_CONCAT把所有stuName拼接 select age,GROUP_CONCAT(stuName) from t_student groupby age;
#按age分组,看每个(岁数)组有多少个stuName select age,COUNT(age) from t_student groupby age;
#按age分组,看每个(岁数)组有多少个stuName,只输出统计总数大于1的 select age,COUNT(age) from t_student groupby age havingcount(age)>1;
#按age分组,看每个(岁数)组有多少个stuName,多加一行计算总和,若是文本为所有元素拼接 select age,COUNT(age) from t_student groupby age withrollup;
selectCOUNT(*) from t_grade; #统计t_grade表内总共有多少条目 selectCOUNT(*) as total from t_grade; #统计t_grade表内总共有多少条目,并把列名 count(*) 改为 total select stuName,COUNT(*) from t_grade groupby stuName; #按stuName分组,看每个(stuName)组有多少条
4.2.2 SUM() 函数
1 2
select stuName,SUM(score) from t_grade where stuName='张一一'; #求某个学生的总分 select stuName,SUM(score) from t_grade groupby stuName; #按stuName分组,看每个(stuName)组的各score总和
4.2.3 AVG() 函数
1 2
select stuName,AVG(score) from t_grade where stuName='张一一'; #求某个学生的总分 select stuName,AVG(score) from t_grade groupby stuName; #按stuName分组,看每个(stuName)组的平均score
4.2.4 MAX() 函数
1 2
select stuName,course,MAX(score) from t_grade where stuName='张一一'; #求某个学生的最高score,并列出course select stuName,MAX(score) from t_grade groupby stuName; #按stuName分组,看每个(stuName)组的最高score #分组前面属性只能写一个属性
4.2.5 MIN() 函数
1 2
select stuName,course,MIN(score) from t_grade where stuName='张一一'; #求某个学生的最低score,并列出course select stuName,MIN(score) from t_grade groupby stuName; #按stuName分组,看每个(stuName)组的最低score #分组前面属性只能写一个属性
4.3 多表连接查询
将两个或两个以上的表按照某个条件连接起来,从中选取需要的数据。
4.3.1 内连接查询
可以查询两个或两个以上的表,最常用。
1 2 3 4 5 6 7
select*from t_book,t_bookType; #数量取两表笛卡尔乘积(两两组合)
select*from t_book,t_bookType where t_book.bookTypeId=t_booktype.id; #数量取两表笛卡尔乘积后,看bookTypeId与id相等的条目
select bookName,author,bookTypeName from t_book,t_bookType where t_book.bookTypeId=t_booktype.id;
select tb.bookName,tb.author,tby.bookTypeName from t_book tb,t_bookType tby where tb.bookTypeId=tby.id; #设置别名,防止多表字段名有重合
select 属性列表 from 表名1left|rightjoin 表名2on 表1.属性1=表2.属性2 #left连接把表1所有属性列出来加上表2匹配的条目,right连接吧表2所有属性列出来加上表1匹配的条目。空值NULL,on限制条件。
1、左连接查询
1
select*from t_book leftjoin t_booktype on t_book.bookTypeId=t_booktype.id; #显示表t_book所有属性
2、右连接查询
1 2
select tb.bookName,tb.author,tby.bookTypeName from t_book tb rightjoin t_bookType tby on tb.bookTypeId=tby.id; #显示表t_bookType全部属性,推荐使用别名。
4.3.3 多条件查询
多个条件之间使用AND连接。
1
select tb.bookName,tb.author,tby.bookTypeName from t_book tb,t_bookType tby where tb.bookTypeId=tby.id AND price>70;
4.4 子查询
在表2中进行查询,查询的某属性是限定在表一的条件中的。
4.4.1 带IN关键字的子查询
一个查询语句的条件可能落在另一个SELECT语句的查询结果中。
1 2
select*from t_book where bookTypeID [NOT] in (select id in t_booktype); #选择表t_book的所有属性显示,筛选bookTypeID 在表t_booktype里的
4.4.2 带比较运算条件的子查询
1 2
select*from t_book where price >= (select price from t_pricelevel where pricelevel=1); #后面括号筛选完成的条件要是数字,不是集合
4.4.3 带Exits关键字的子查询
判断性质:假如子查询语句查询到记录则进行外层查询,子查询为空不执行外层查询。
1 2
select*from t_book where [NOT] EXITS (select*from t_booktype); #后面括号筛选得到空,则不执行前面的查询
4.4.4 带ANY关键字的子查询
满足任一条件即可。
1 2
select*from t_book where price >=any (select price from t_pricelevel); #后面括号筛选完成的条件是集合
4.4.5 带ALL关键字的子查询
满足所有条件。
1 2
select*from t_book where price >=all (select price from t_pricelevel); #后面括号筛选完成的条件是集合
4.5 合并查询
使用UNION关键字将所有查询结果合并到一起,去除相同记录。UNION ALL不去除重复记录。
1 2 3 4
select id from t_book; #(1,2,3,4) select id from t_booktype; #(1,2,3,6) select id from t_book UNIONselect id from t_booktype; #(1,2,3,4,6) select id from t_book UNIONALLselect id from t_booktype; #(1,2,3,4,1,2,3,6)
#多列索引,uName,password两列属性指向一个索引 createtable t_u3(id int, uName varchar(20), password varchar(20), INDEX index_uName_password(uName,password));
方法2:为已经存在的表添加索引:
1 2 3
create INDEX index_uName ON t_u4(uName); #新增普通单列索引 createUNIQUE INDEX index_uName ON t_u4(uName); #新增唯一性单列索引 create INDEX index_uName_password ON t_u4(uName,password); #新增多列索引
方法3:使用alter方法创建索引:
1 2 3
alterTABLE t_u5 ADD INDEX index_uName(uName); #新增普通单列索引 alterTABLE t_u5 ADDUNIQUE INDEX index_uName(uName); #新增唯一性单列索引 alterTABLE t_u5 ADD INDEX index_uName_password(uName,password); #新增多列索引
5.3 删除索引
1 2 3 4
#DROP INDEX 索引名 ON 表名;
DROP INDEX index_userName ON t_u5; DROP INDEX index_userName_password ON t_u5; #删除多列索引
UPDATE v1 SET bookName='java very good',price=200WHERE id=5;
6.5.3 删除视图(数据)
1
DELETEFROM v1 WHERE id=5;
6.6 删除视图
删除数据库中已经存在的视图,删除视图并不会删除数据,只是删除视图定义。
1
DROPVIEW IF EXISTS view1;
7 触发器(TRIGGER)
执行某项操作(INSERT、UPDATE、DELETE)时候自动触发执行预设好的相对应操作。
如在表a添加数据时表b里的对应属性也进行一个变化。
相同的表相同的操作只能创建一个对应的触发器。
7.1 创建使用触发器
单个执行语句的触发器:
注意执行语句where 后面的部分old和new
old表示插入之前的值,old用在删除和修改
new表示新插入的值,new用在添加、更新和修改
1 2 3 4 5 6
#创建trigger:在insert插入新数据操作之后 更新书的数量 new表示插入的条目 CREATETRIGGER trig_book AFTER INSERT ON t_book FOREACHROW UPDATE t_bookType SET bookNum=bookNum+1WHERE new.bookTypeId=t_booktype.id;
#创建触发器 DELIMITER | CREATETRIGGER trig_book2 AFTER DELETE ON t_book FOREACHROW BEGIN UPDATE t_bookType SET bookNum=bookNum-1WHERE old.bookTypeId=t_booktype.id; INSERTINTO t_log VALUES(NULL,NOW(),'在book表里删除了一条数据'); #mysql里NOW()表示当前时间 DELETEFROM t_test WHERE old.bookTypeId=t_test.id; #顺便把t_test的一条也删掉 END | DELIMITER;
CREATEFUNCTION sp_name ([func_parameter[,...]]) RETURNS type [characteristic ...] routine_body
sp_name 参数是存储过程/或存储函数的名称
proc_parameter 表示存储过程的参数列表,每个参数格式 [IN|OUT|INOUT] param_name type IN 表示输入参数;OUT 表示输出参数;INOUT 表示既可以是输入,也可以是输出;param_name 参数是 存储过程的参数名称;type 参数指定存储过程的参数类型,该类型可以是 MySQL 数据库的任意数据类型
func_parameter:param_name type
type:Any valid MySQL data type
characteristic 参数指定存储过程的特性 可取:LANGUAGE SQL| [NOT] DETERMINISTIC| { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA }| SQL SECURITY { DEFINER | INVOKER }| COMMENT 'string'
DELIMITER && CREATEPROCEDURE pro_book ( IN bT INT,OUT count_num INT) READSSQL DATA BEGIN SELECTCOUNT(*) FROM t_book WHERE bookTypeId=bT; END && DELIMITER ;
CALL pro_book(1,@total); #调用存储过程
DELIMITER && CREATEFUNCTION func_book (bookId INT) RETURNSVARCHAR(20) BEGIN RETURN ( SELECT bookName FROM t_book WHERE id=bookId ); END && DELIMITER ;
SELECT func_book(2); #调用存储函数
9.1.2 修改存储过程或函数:
1 2
ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...] #characteristic:参数含义类似
9.1.3 调用存储函数/过程
调用存储过程 CALL sp_name([param_name[,...]);
调用存储函数 sp_name([param_name[,...]);
9.1.4 查看现有存储过程/函数
1 2 3 4 5
#SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern'] #查看状态
SHOWPROCEDURE STATUS LIKE'pro_book';
SHOW CREATE {PROCEDURE | FUNCTION} sp_name #查看定义
9.1.5 删除存储函数/过程
1 2 3
#DROP {PROCEDURE | FUNCTION} [IF EXISTS] sp_name
DROPPROCEDURE pro_user3;
9.2 存储函数变量
9.2.1 存储函数/过程中定义变量
1
DECLARE var_name[,...] type [DEFAULTvalue]
定义的变量不赋值时默认插入为NULL
1 2 3 4 5 6 7 8 9 10 11
#t_user有id,uName,password DELIMITER && CREATEPROCEDURE pro_user() BEGIN DECLARE a,b VARCHAR(20) ; INSERTINTO t_user VALUES(NULL,a,b); END && DELIMITER ;
[begin_label:]LOOP Statement_list END LOOP [ end_label ]
LEAVE 语句主要用于跳出循环控制。语法形式如下:
1
LEAVE label
举例:循环插入指定参数条数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14
DELIMITER && CREATEPROCEDURE pro_user7(IN totalNum INT) BEGIN aaa:LOOP SET totalNum=totalNum-1; IF totalNum=0THEN LEAVE aaa ; ELSEINSERTINTO t_user VALUES(totalNum,'2312312','2321312'); END IF ; END LOOP aaa ; END && DELIMITER ; DELETEFROM t_user; CALL pro_user7(11); #调用存储过程
[ begin_label : ] REPEAT Statement_list UNTIL search_condition END REPEAT [ end_label ]
举例:
1 2 3 4 5 6 7 8 9 10 11 12 13
DELIMITER && CREATEPROCEDURE pro_user9(IN totalNum INT) BEGIN REPEAT SET totalNum=totalNum-1; INSERTINTO t_user VALUES(totalNum,'2312312','2321312'); UNTIL totalNum=1 END REPEAT; END && DELIMITER ; DELETEFROM t_user; CALL pro_user9(11); #调用存储过程
9.4. 6 WHILE 语句
1 2 3
[ begin_label : ] WHILE search_condition DO Statement_list END WHILE [ end_label ]
举例:
1 2 3 4 5 6 7 8 9 10 11 12
DELIMITER && CREATEPROCEDURE pro_user10(IN totalNum INT) BEGIN WHILE totalNum>0 DO INSERTINTO t_user VALUES(totalNum,'2312312','2321312'); SET totalNum=totalNum-1; END WHILE ; END && DELIMITER ; DELETEFROM t_user; CALL pro_user10(11); #调用存储过程