加载模块失败
insmod xxx.ko报错 insmod: ERROR: could not insert module xxx.ko: Unknown symbol in module
1 | modinfo xxx.ko | grep depends #查看依赖的模块(lsmod 命令可以查看内核中已经的模块) |
insmod xxx.ko报错 insmod: ERROR: could not insert module xxx.ko: Unknown symbol in module
1 | modinfo xxx.ko | grep depends #查看依赖的模块(lsmod 命令可以查看内核中已经的模块) |
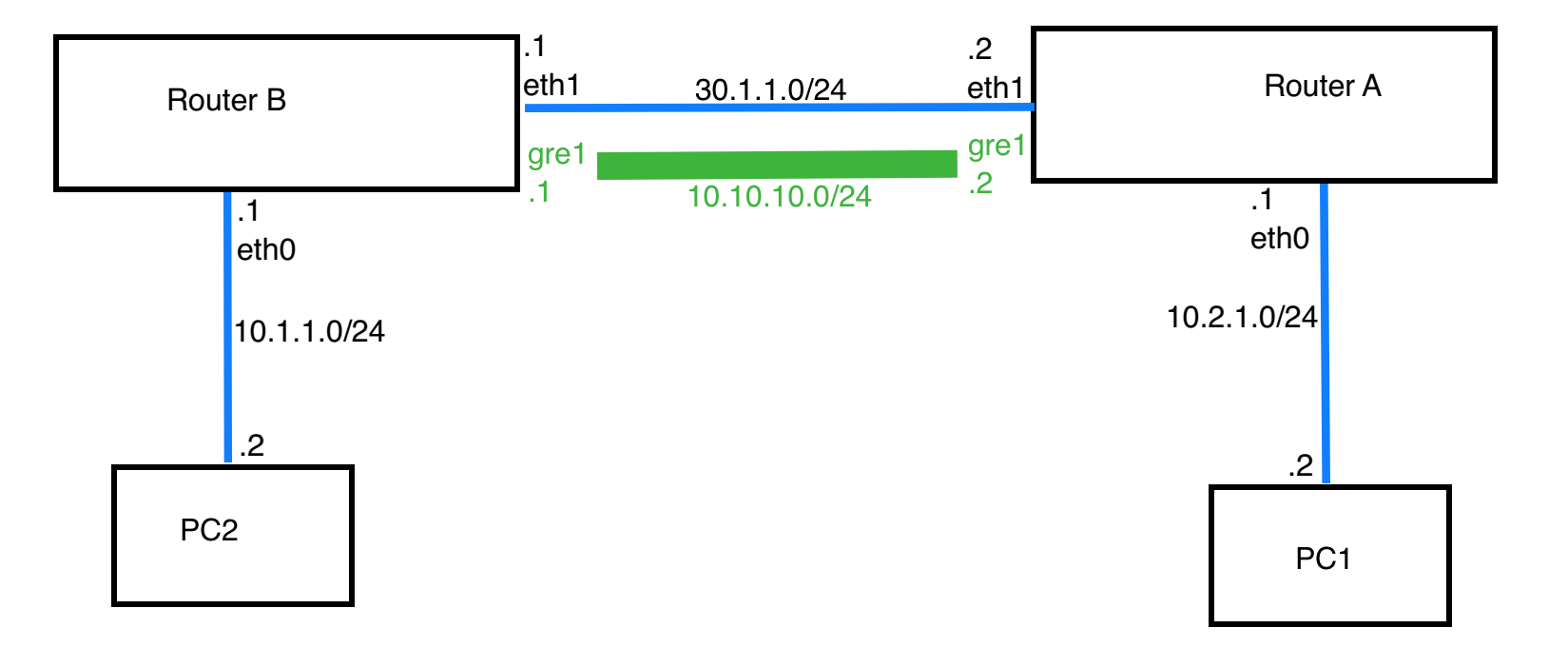
1 | #routerB |
1 | #routerA |
1 | #routerB and routerA |
routerB ping -I 10.10.10.1 10.10.10.2 -c2 通路
routerA ping -I 10.10.10.2 10.10.10.1 -c2 通路
routeB ip route add 10.2.1.0/24 via 10.10.10.2
routeA ip route add 10.1.1.0/24 via 10.10.10.1
PC2 ping 10.2.1.2 通路
PC1 ping 10.1.1.2 通路
1 | # root @ routerA in / [11:37:33] |
1 | ip link set gre1 down |
查看内核是否支持gre
1 | grep GRE /boot/config-$(uname -r) |
kernel: conntrack: generic helper won't handle protocol 47. Please consider loading the specific helper module.
1 | modprobe nf_conntrack_proto_gre |
若需要grep nf_nat_proto_gre || modprobe nf_nat_proto_gre
GRE是将一个数据包封装到另一个数据包中,因此你可能会遇到GRE的数据报大于网络接口所设定的数据包最大尺寸的情况。解决这种问题的方法是在隧道接口上配置ip tcp adjust-mss 1436。另外,虽然GRE并不支持加密,但是你可以通过tunnel key命令在隧道的两头各设置一个密钥。这个密钥其实就是一个明文的密码。或者使用gre over ipsec,那样就比较复杂了再另说。
GRE隧道没有状态控制,可能隧道的一端已经关闭,而另一端仍然开启。这一问题的解决方案就是在隧道两端开启keepalive数据包。它可以让隧道一端定时向另一端发送keepalive数据,确认端口保持开启状态。如果隧道的某一端没有按时收到keepalive数据,那么这一侧的隧道端口 也会关闭。
kernel/net/ipv4/ip_gre.c
1 | static int ipgre_rcv(struct sk_buff *skb, const struct tnl_ptk_info *tpi) |
kernel/net/ipv4/ip_tunnel.c
1 | /* Fallback tunnel: no source, no destination, no key, no options |
1 | modinfo ip_gre |
隧道是正常通信的
1 | [ 2990.916244] output info dev:eth1 protocol:0x0800, 20.1.1.1->20.1.1.2 protocol:47 ip csum:578(1400) len:92 |
隧道是不通的
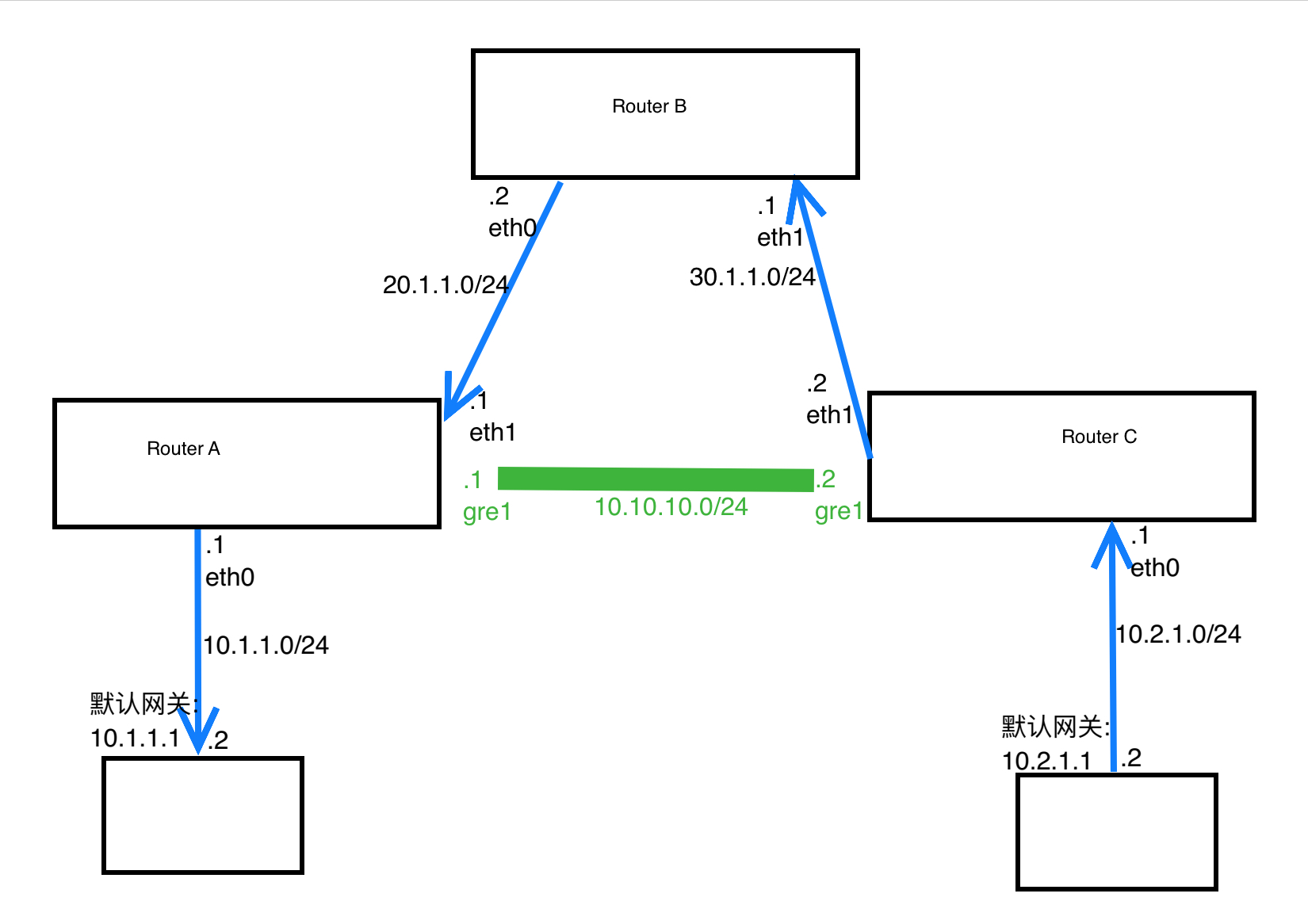
1 | [ 3498.496802] input info dev:eth1 protocol:0x0800, 20.1.1.2->20.1.1.1 protocol:47 ip csum:709a(28826) len:92 |
gre用于同网段的A类地址(即公网地址)的两个设备之间,跨网段是无法建立隧道的(除非关闭RouterB的NAT)。
1 | apt install pimd |
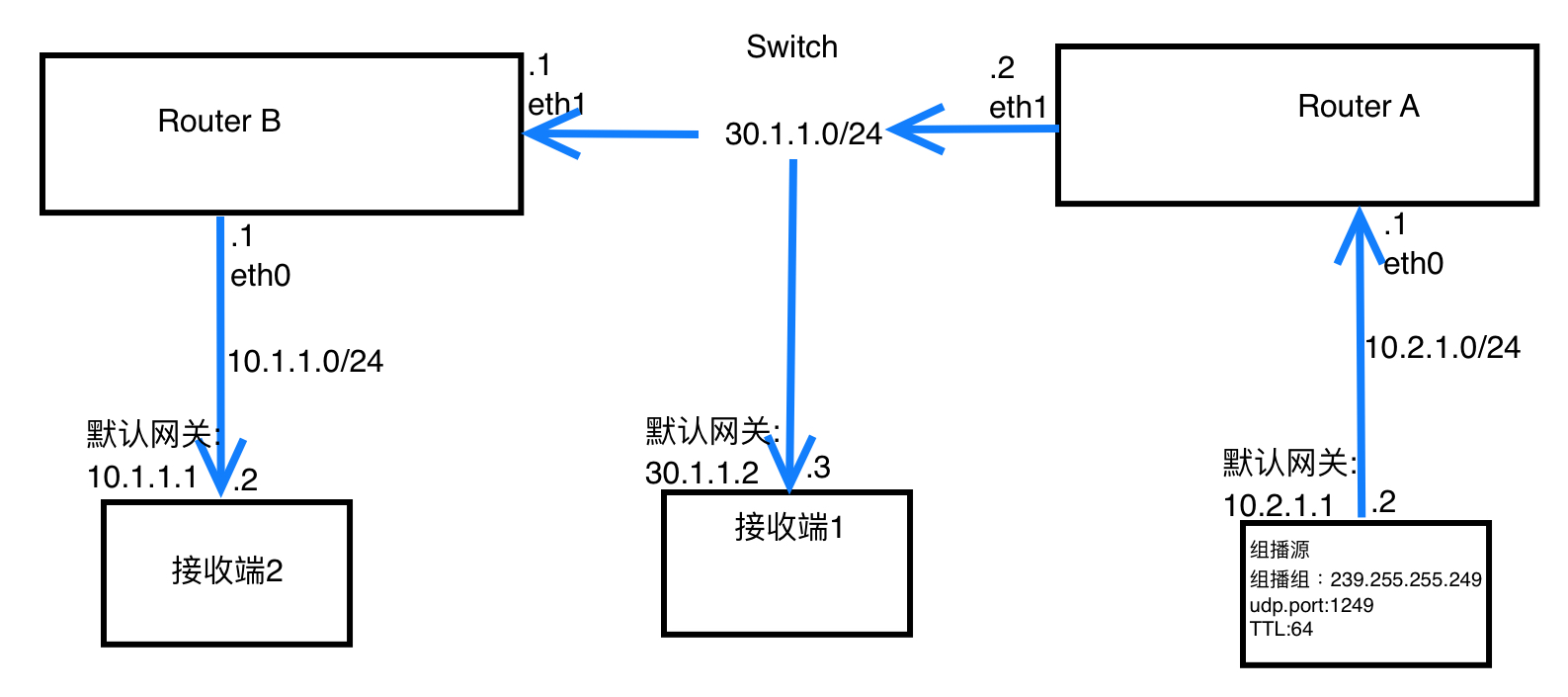
参考《linux网络1_ospf》分别对routeA和routeB进行ospf功能配置,或者设置默认路由,使得组播源、接收端1、接收端2这三者之间能两两相互ping通
参考《vlc组播测试Server及Client使用》
1 | # root @ routerA in / [14:27:40] |
1 | # root @ routerB in / [14:33:40] |
1 | $ journalctl -u pimd.service |
1 | # root @ routerA in / [15:04:54] |
routerA的组播路由表出现了 (10.2.1.2, 239.255.255.249) Iif: eth0 Oifs: eth1
1 | # root @ routerB in / [15:08:16] |
routerB的组播路由表出现了 (30.1.1.2, 239.255.255.249) Iif: eth1 Oifs: eth0
备注:可以看到routerA和routerB的汇聚点选举结果为 RP Address:30.1.1.2
接收端1和接收端2上面的vlc都能播放udp://@239.255.255.249:1249的视频。
1 | apt install quagga |
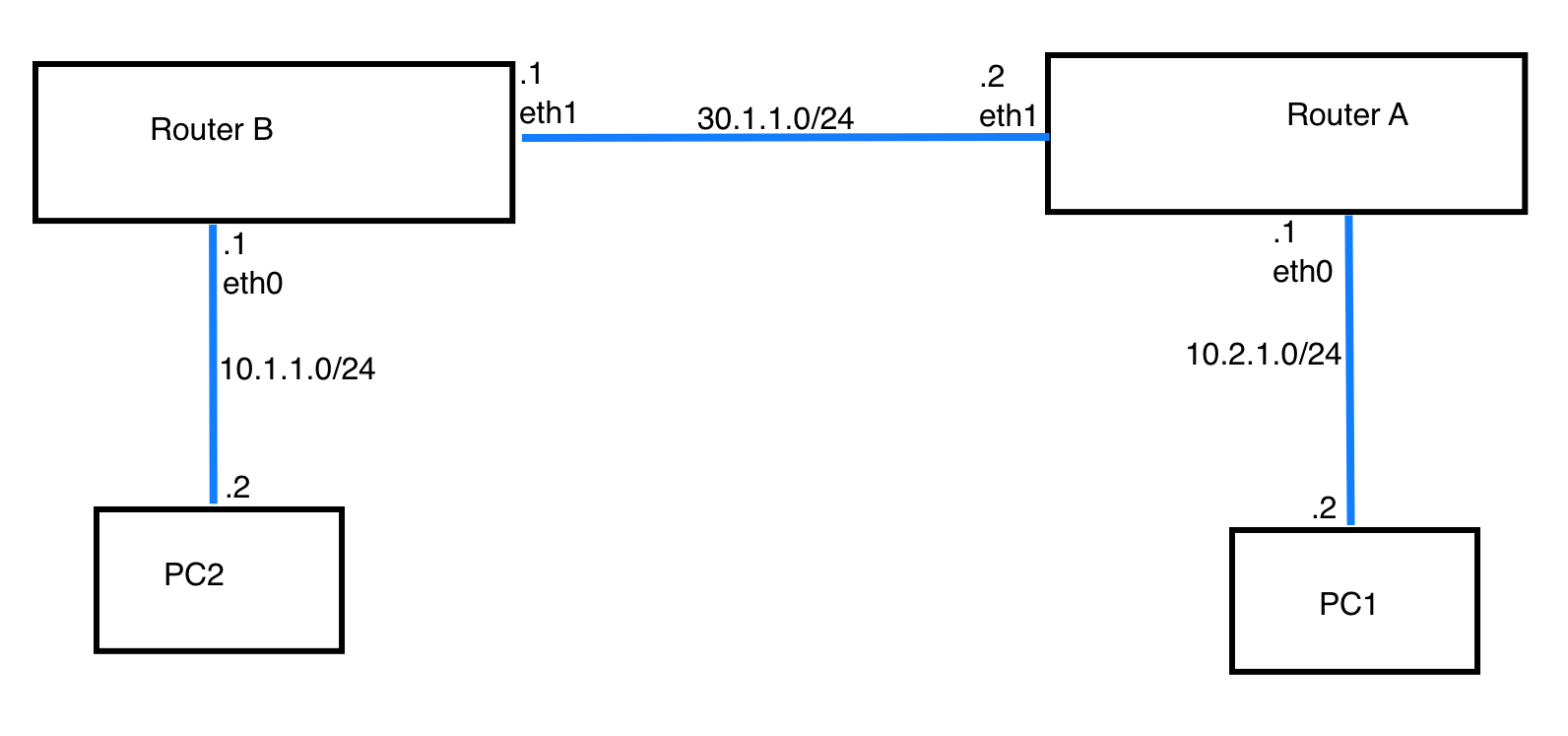
1 | # root @ routerA in / [11:37:11] |
1 | # root @ routerB in / [11:39:11] |
1 | $ journalctl -u quagga.service |
1 | # root @ routerA in / [11:41:51] |
routerA的路由表出现了 10.1.1.0/24 via 30.1.1.1 dev eth1 proto zebra metric 20
1 | # root @ routerB in / [11:39:49] |
routerB的路由表出现了 10.2.1.0/24 via 30.1.1.2 dev eth1 proto zebra metric 20
PC1 ping PC2
1 | # zh @ li in ~ [11:44:36] |
PC2 ping PC1
1 | # zh @ li in ~ [11:44:36] |
telnet localhost 2601 密码在/etc/quagga/zebra.conftelnet localhost 2604 密码在/etc/quagga/ospfd.conf
1 | # root @ routerA in / [13:53:38] C:1 |
igmp和pim介绍
VLC是一种开源的媒体播放器,但同时又可以用于组播测试。可以用VLC搭建组播Server,也可以用VLC作客户端接受组播流。
注意:默认VLC图形方式下打出的组播流其IP报头中的TTL=1。
注意:默认UDP的组播流输出接口是根据系统本地的路由表来选择的。比如:
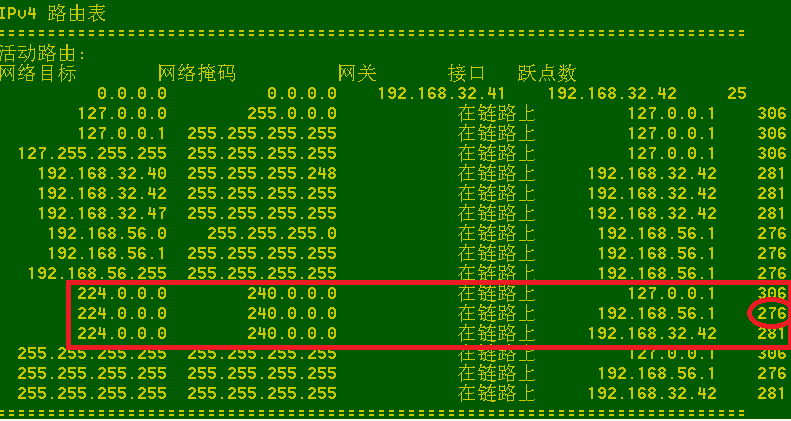
如果输出组播的IP地址为239.10.1.1,那么根据上述路由表组播流将发往192.168.56.1那个接口。因为该接口的路由metric相对较小(276)。
1 | route add 239.0.0.0 mask 255.0.0.0 192.168.1.100 |
1 | vlc -vvv D:\bak\others\组播测试片源\hello.mp4 --sout udp:239.10.1.1:1234 --ttl 10 |
1 | vlc udp://@239.10.1.1:1234 |
1 | vlc -vvv hello.mp4 --sout "#transcode{vcodec=h264,vb=0,scale=0,acodec=mpga,ab=128,channels=2,samplerate=44100}:rtp{dst=239.10.1.1,port=4321,mux=ts,ttl=20}" |
1 | vlc rtp://@239.10.1.1:4321 |
1 | vlc -vvv sample1.avi --sout "#transcode{vcodec=h264,vb=0,scale=0,acodec=mpga,ab=128,channels=2,samplerate=44100}:rtp{sdp=rtsp://:8554/test}" |
1 | vlc rtsp://172.16.1.1:8554/test |
1 | vlc -vvv sample1.avi --sout "#transcode{vcodec=h264,vb=0,scale=0,acodec=mpga,ab=128,channels=2,samplerate=44100}:http{mux=ffmpeg{mux=flv},dst=:8080/test}" |
1 | vlc http://172.16.1.1:8080/test |
在 Archlinux 中,使用一条命令即可对整个系统进行更新
1 | pacman -Syyu |
如果你已经使用pacman -Sy将本地的包数据库与远程的仓库进行了同步,也可以只执行:pacman -Su
1 | pacman -S 包名 #例如,执行 pacman -S firefox 将安装 Firefox。你也可以同时安装多个包,只需以空格分隔包名即可。 |
1 | pacman -R 包名 #该命令将只删除包,保留其全部已经安装的依赖关系 |
1 | pacman -Ss 关键字 #在仓库中搜索含关键字的包。 |
1 | pacman -Sw 包名 #只下载包,不安装。 |
在kernel驱动程序中读写文件,没有标准库可用,需要用kernel提供的一些函数
1 |
|
1 | //filename: 表明要打开或创建文件的名称(包括路径部分)。需要先挂载文件系统再挂载驱动才能打开文件。 |
1 | //参数loff_t * pos所指向的值要初始化,表明从文件的什么地方开始读写。 |
这两个函数的第二个参数buffer,前面有__user修饰符,这就要求buffer指针应该指向用户空间的内存,如果传入kernel空间的指针,就会返回失败-EFAULT
但在Kernel中,我们一般不容易生成用户空间的指针,或者不方便独立使用用户空间内存。想要使这两个读写函数使用kernel空间的buffer指针也能正确工作,就需要使用set_fs()宏/函数
1 | //获取kernel当前对内存地址检查的处理方式,默认情况下是USER_DS,即对用户空间地址检查并做变换。 |
要在对内存地址做检查变换的函数中使用内核空间地址,可以用set_fs(KERNEL_DS)进行设置
1 | mm_segment_t old_fs = get_fs(); |
还有一些其它的内核函数参数也用__user修饰的参数,在kernel中需要用kernel空间的内存代替时,都可以使用类似办法。
1 | //第二个参数一般传递NULL值,也有用current->files作为实参的 |
使用以上函数的其它注意点:
1 | # zh @ li in ~ [6:24:36] |
学习过程参考视频教程:java1234网站《一头扎进mysql》
源码及视频网盘:链接
数据库(Database)是按照数据结构来组织、存储和管理数据的仓库。
我们也可以将数据存储在文件中,但是在文件中读写数据速度相对较慢。
使用关系型数据库管理系统(RDBMS)来存储和管理的大数据量。所谓的关系型数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。
RDBMS 即关系数据库管理系统(Relational Database Management System)的特点:
| 整数类型 | 字节数 | 无符号(unsigned)范围 | 有符号(signed)范围 |
|---|---|---|---|
| TINYINT | 1 | 0~255 | -128~127 |
| SMALLINT | 2 | 0~65535 | -32768~32767 |
| MEDIUMINT | 3 | 0~16777215 | -8388608~8388607 |
| INT | 4 | 0~4294967295 | -2147483648~2147483647 |
| INTEGER | 4 | 0~4294967295 | -2147483648~2147483647 |
| BIGINT | 8 | 0~18446744073709551615 | -9223372036854775808~9223372036854775807 |
INTEGER和INT是相同的,一般定义主键使用INT即可。默认是有符号情况,无符号要特别说明。
浮点型在数据库中存放的是近似值,而定点类型在数据库中存放的是精确值。
数据类型精度有无符号的范围
float32位中,有1位符号位,8位指数位,23位尾数位,实际的范围是-2128—2127,约为-3.4E38—3.4E38
double64位中,1位符号位,11位指数位,52位尾数位,范围约是-1.7E308—1.7E308
float和double精度问题:参考博客
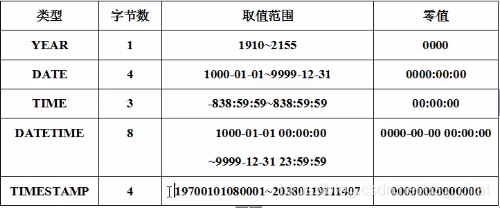
常用 DATA,TIME,DATATIME
数据类型大小用途
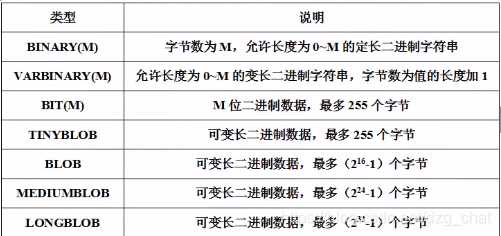
存一些图片视频,一般存在web目录下读取快,存数据库慢。
退出Mysql:quit
显示所有数据库:show databases;
创建数据库:create database Name; Name最好有一定规范,如db_book1
删除数据库:drop database Name;
表是数据库存储数据的基本单位,一个表包含若干字段或记录。
1 | CREATE TABLE table_name ( |
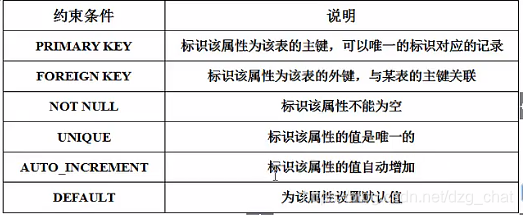
表的常见约束条件:
创建图书类别表:
1 | use db_book; |
创建图书类型表:
并将图书的类别ID,做外键关联使用。
1 | create table t_book( |
若之前表已经存在了,则:
1 | create table Connect( |
注意这里的符号是数字1左侧英文输入状态下的 ` 不是单引号 ’
查看基本表结构:DESCRIBE/DESC 表名;
详细结构:SHOW create table 表名;
显示本数据库内的所有表:SHOW tables
1 | desc t_booktype; |

修改表名: alter table t_book rename t_book2;
修改t_book表的bookName字段名为bookName2,数据类型为 varchar(20): alter table t_book change bookName bookName2 varchar(20);
增加字段名: alter table t_book add authorage varchar(10);
带约束增加
1 | #加到最前面一列 |
删除字段名: alter table t_book drop testField;
drop table 表名;
有依赖关系的时候先删掉子表再删主表。
先创建一个数据表:
1 | create table t_student( |
插入数据: 注意里面是使用的单引号
1 | insert into db_book.t_student (id,stuName,age,gender,gradeName) values (1,'张一',18,'男','大一'); |
或者后面多组:
1 | insert into db_book.t_student (id,stuName,age,gender,gradeName) values (9,'张九',20,'女','大二'),(10,'张十',20,'女','大四'); |
给表取别名:表名 表别名
select * from t_book where id=1; 等价 select * from t_book tb where tb.id=1;
字段取别名:属性 [AS] 属性别名
select tb.bookName [AS] tbNa from t_book tb where tb.id=1;
1 | #select 字段1,字段2,字段3... from 表名; |
1 | select 指定字段1,指定字段3... from 表名; |
1 | #select 字段1,字段2... from 表名 where 条件表达式; |
指定条件删除字段:
1 | delete from t_student where id=4; |
1 | #select 字段1,字段2,字段3... from 表名 where 字段 [NOT] IN (元素1.元素2…); |
1 | #select 字段1,字段2,字段3... from 表名 where 字段 [NOT] BETWEEN 取值a AND 取值b; |
1 | #select 字段1,字段2,字段3... from 表名 where 字段 [NOT] LIKE ‘字符串’; |
1 | #select 字段1,字段2,字段3... from 表名 where 字段 IS [NOT] NULL; |
1 | #select 字段1,字段2,字段3... from 表名 where 条件表达式1 AND 条件表达式2 AND 条件表达式3 AND ... |
1 | #select 字段1,字段2,字段3... from 表名 where 条件表达式1 OR 条件表达式2 OR 条件表达式3 OR ... |
1 | #select distinct 字段名 from 表; |
1 | #select 字段1,字段2,... from 表名 order by 属性名 [ASC|DESC] |
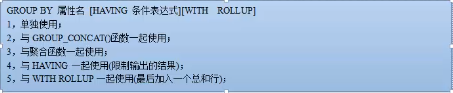
一般不单独使用,常和聚合函数一起使用,一定注意使用的时候各个符号。
1 | #按age分组,看每个(岁数)组有哪些stuName,GROUP_CONCAT把所有stuName拼接 |
1 | #select 字段1,字段2... from 表名 limit 初始位置,记录数, |
先创建一个相关数据表:
1 | create table t_garde( |

1 | select COUNT(*) from t_grade; #统计t_grade表内总共有多少条目 |

1 | select stuName,SUM(score) from t_grade where stuName='张一一'; #求某个学生的总分 |

1 | select stuName,AVG(score) from t_grade where stuName='张一一'; #求某个学生的总分 |

1 | select stuName,course,MAX(score) from t_grade where stuName='张一一'; #求某个学生的最高score,并列出course |

1 | select stuName,course,MIN(score) from t_grade where stuName='张一一'; #求某个学生的最低score,并列出course |
将两个或两个以上的表按照某个条件连接起来,从中选取需要的数据。
可以查询两个或两个以上的表,最常用。
1 | select * from t_book,t_bookType; #数量取两表笛卡尔乘积(两两组合) |
外链接可以查询某一张表的所有信息,就是把一张表不全的部分补进来,left right决定谁合并到谁之中。
1 | select 属性列表 from 表名1 left|right join 表名2 on 表1.属性1=表2.属性2 |
1、左连接查询
1 | select * from t_book left join t_booktype on t_book.bookTypeId=t_booktype.id; #显示表t_book所有属性 |
2、右连接查询
1 | select tb.bookName,tb.author,tby.bookTypeName from t_book tb right join t_bookType tby on tb.bookTypeId=tby.id; |
多个条件之间使用AND连接。
1 | select tb.bookName,tb.author,tby.bookTypeName from t_book tb,t_bookType tby where tb.bookTypeId=tby.id AND price>70; |
在表2中进行查询,查询的某属性是限定在表一的条件中的。
一个查询语句的条件可能落在另一个SELECT语句的查询结果中。
1 | select * from t_book where bookTypeID [NOT] in (select id in t_booktype); |
1 | select * from t_book where price >= (select price from t_pricelevel where pricelevel=1); |
判断性质:假如子查询语句查询到记录则进行外层查询,子查询为空不执行外层查询。
1 | select * from t_book where [NOT] EXITS (select * from t_booktype); |
满足任一条件即可。
1 | select * from t_book where price >= any (select price from t_pricelevel); |
满足所有条件。
1 | select * from t_book where price >= all (select price from t_pricelevel); |
使用UNION关键字将所有查询结果合并到一起,去除相同记录。UNION ALL不去除重复记录。
1 | select id from t_book; #(1,2,3,4) |
所有字段插入数据:
1 | #insert into 表名 values(值1,值2,值3...); |
指定字段插入数据:
1 | #insert into 表名(属性1,属性2,属性n) values(值1,值2,值3...); |
同时插入多条记录:
1 | #insert into 表名[(属性列表)] values (取值列表1),(取值列表2),...(取值列表n); |
表里的一些属性值发生了变化,及时更新
1 | #update 表名 set 属性1 =取值1,属性2=取值2...属性n=取值n where 条件表达式; |
1 | #delete from 表名 where [条件表达式] |
索引类似图书的目录,方便快速定位,查找指定内容,提高查询速度。
索引是数据库的一个对象,数据库中的一列或者多列组成,它不能独立存在,必须对某个表对象进行依赖。
索引保存在information_schema数据库里的STATISTICS表中。
查看数据库 db_book 内所有索引:
1 | select * from mysql.`innodb_index_stats` a where a.`database_name` = 'db_book'; |
查看当前table的索引:
1 | show index from tableName; |

创建的关键字 INDEX
一般主键在创建时默认就是唯一性索引。
方法1:最开始创建表的时候添加索引:

1 | #普通 单列 索引 |
方法2:为已经存在的表添加索引:

1 | create INDEX index_uName ON t_u4(uName); #新增普通单列索引 |
方法3:使用alter方法创建索引:

1 | alter TABLE t_u5 ADD INDEX index_uName(uName); #新增普通单列索引 |
1 | #DROP INDEX 索引名 ON 表名; |
可参考:博客

ALGORITHM表示视图选择的算法(可选参数)
WITH CHECK OPTION表示更新视图时要保证在该试图的权限范围之内(可选参数)
1 | CREATE VIEW v1 AS SELECT * FROM t_book; #用t_book所有字段生成视图v1 |
同一个数据库下不同表:
1 | create view v4 as (select * from table1) union all (select * from table2); #合并查询 |
或:
1 | create view v5 as select bookName,bookTypeName from t_book,t_booktype where t_book.bookTypeID=t_booktype.id; |
不同数据库下的不同表:
1 | #在数据库1 目录下创建 |
通过指令或数据库图形管理工具查看。
1 | DESC view1; #基本的视图内容信息:字段名、类型等 |
方法1:

1 | #视图v1有4个字段,改为只有bookName和price |
方法2:

1 | #视图v1只有bookName和price,改为t_book所有的字段 |
1 | #视图v1有id,bookName,price,author,bookTypeID |
1 | UPDATE v1 SET bookName='java very good',price=200 WHERE id=5; |
1 | DELETE FROM v1 WHERE id=5; |
删除数据库中已经存在的视图,删除视图并不会删除数据,只是删除视图定义。
1 | DROP VIEW IF EXISTS view1; |
执行某项操作(INSERT、UPDATE、DELETE)时候自动触发执行预设好的相对应操作。
如在表a添加数据时表b里的对应属性也进行一个变化。
相同的表相同的操作只能创建一个对应的触发器。
单个执行语句的触发器:

注意执行语句where 后面的部分old和new
1 | #创建trigger:在insert插入新数据操作之后 更新书的数量 new表示插入的条目 |
多条执行语句:

默认mysql是遇到一个分号 ; 执行一次的。
DELIMITER | 是告诉mysql解释器不要将多条程序体里面单条语句的分号 ;直接执行,是作为一个程序体的。也可以使用 $$ // 等表示
可参考:厚积_薄发博客
1 | #创建触发器 |
上面函数的作用是:当删除 t_book 里面 id=5的数据时,触发在
t_bookType 表中 bookNum数量-1t_log 中加入一条记录t_test 里面删除了和之前记录id相等的数据 old.bookTypeId=t_test.id查看触发器的状态:
1 | SHOW TRIGGERS; #列出来所有的 |
注意结束符号 ;之前是否有空格或者全半角区别,可能引起错误。
1 | DROP TRIGGER trig_book ; |
触发器补充介绍:硕果累累的博客
获取当前时间的语句:
1 | select now(); |
其他类似:time、year 、quarter、month、week、day、hour、minute、second
与时间相关函数:
名称作用CURDATE()返回当前日期CURTIME()返回当前时间MONTH(d)返回当前日期d中的月份值
1 | SELECT CURDATE(),CURTIME(),MONTH(birthday) AS m FROM table; #birthday是列名,MONTH(birthday)重命名为m |
CHAR_LENGTH(s)计算字符串字符数UPPER(s)转为大写LOWER(s)转为小写CONCAT(s1,s2...)拼接多个字符串LEFT(str,len) RIGHT(str,len)返回字符串str 从左、右起len长的子串。REVERSE(str)把str倒序1 | SELECT uName,CHAR_LENGTH(uName),UPPER(uName) up,LOWER(uName) low,concat(uName,upper(uName)) FROM t_u1; |
输出:

1 | select uName,left(uName,2),right(uName,2) from t_u1; |
其他还有很多字符串函数可以需要的时候再查阅使用:
1 | ASCII(str), |
ABS(x)绝对值SQRT(x)平方根MOD(x,y)求余ROUND(X,Y)X的Y位四舍五入小数CEIL(x)、CEILING(x)向上取整FLOOR(x)向下取整POW(x,y)、POWER(x,y)幂运算,求x的y次方幂1 | select num,ABS(num),SQRT(num),MOD(num,3) from t_t; #计算num列的绝对值和对3求余 |
PASSWORD(str)对密码加密,不可逆MD5(str)、SHA5()MD5校验、SHA5校验ENCODE(str,pswd_str)加密字符串,结果必须用BLOB类型保存DECODE(crypt_str,pswd_str)解密字符串在插入数据的时候设置加密的格式、加密数据和加密解密的钥匙:
1 | #t_t有id,birthday,uName,num,password,pp 其中pp是blob类型 |
存储过程和函数是在数据库中定义一些 SQL 语句的集合,然后直接调用这些存储过程和函数来执行已经定义好的 SQL 语句。存储过程和函数可以避免开发人员重复的编写相同的 SQL 语句。而且,存储过程和函数是在 MySQL服务器中存储和执行的,可以减少客户端和服务器端的数据传输;
区别:
创建存储过程或函数:
1 | CREATE PROCEDURE sp_name ([proc_parameter[,...]]) |
创建存储过程/函数示例sql语句
1 | DELIMITER && |
1 | ALTER {PROCEDURE | FUNCTION} sp_name [characteristic ...] |
调用存储过程 CALL sp_name([param_name[,...]);
调用存储函数 sp_name([param_name[,...]);
1 | #SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern'] #查看状态 |
1 | #DROP {PROCEDURE | FUNCTION} [IF EXISTS] sp_name |
1 | DECLARE var_name[,...] type [DEFAULT value] |
定义的变量不赋值时默认插入为NULL
1 | #t_user有id,uName,password |
1 | #方式1 直接赋值 |
1 | #分别表示直接赋值和查询结果赋值 |
查询语句可能查询出多条记录,在存储过程和函数中使用游标来逐条读取查询结果集中的记录。游标必须声明在处理程序之前,并且声明在变量和条件之后。
游标的使用包括
DECLARE cursor_name CURSOR FOR select_statement ;OPEN cursor_name;FETCH cursor_name INTO var_name [,var_name ... ];CLOSE cursor_name;1 | DELIMITER && |
存储过程和函数中可以使用流程控制来控制语句的执行。MySQL 中可以使用 IF 语句、CASE 语句、LOOP语句、LEAVE 语句、ITERATE 语句、REPEAT 语句和 WHILE 语句来进行流程控制。
1 | IF search_condition THEN statement_list |
举例:根据传入的id查询,结果数量大于0时更新这个id对应的name,否则新插入一条数据
1 | DELIMITER && |
1 | CASE case_value |
举例:传入id,查询的结果数量为1时更新,2时插入,其他情况插入另一条
1 | DELIMITER && |
LOOP 语句可以使某些特定的语句重复执行,实现一个简单的循环。但是 LOOP 语句本身没有停止循环的语句,必须是遇到 LEAVE 语句等才能停止循环。LOOP 语句的语法的基本形式如下:
1 | [begin_label:]LOOP |
LEAVE 语句主要用于跳出循环控制。语法形式如下:
1 | LEAVE label |
举例:循环插入指定参数条数据
1 | DELIMITER && |
ITERATE 语句也是用来跳出循环的语句。但是,ITERATE 语句是跳出本次循环,然后直接进入下一次循环。基本语法:
1 | ITERATE label ; |
示例:指定插入次数参数为3的时候不插入,其余在0之前的都插入
1 | DELIMITER && |
REPEAT 语句是有条件控制的循环语句。当满足特定条件时,就会跳出循环语句。REPEAT 语句的基本语法形式如下:
1 | [ begin_label : ] REPEAT |
举例:
1 | DELIMITER && |
1 | [ begin_label : ] WHILE search_condition DO |
举例:
1 | DELIMITER && |
备份数据可以保证数据库中数据的安全,需要定期的进行数据库备份,可以备份数据表和整个数据库。
可以使用命令备份,也可以使用图形管理工具直接导出备份。
1 | mysqldump -username -p dbname table1 table2 ... > BackupName.sql |
使用命令或者图形界面导入还原数据。
1 | mysql -u root -p [dbname] < backup.sql |